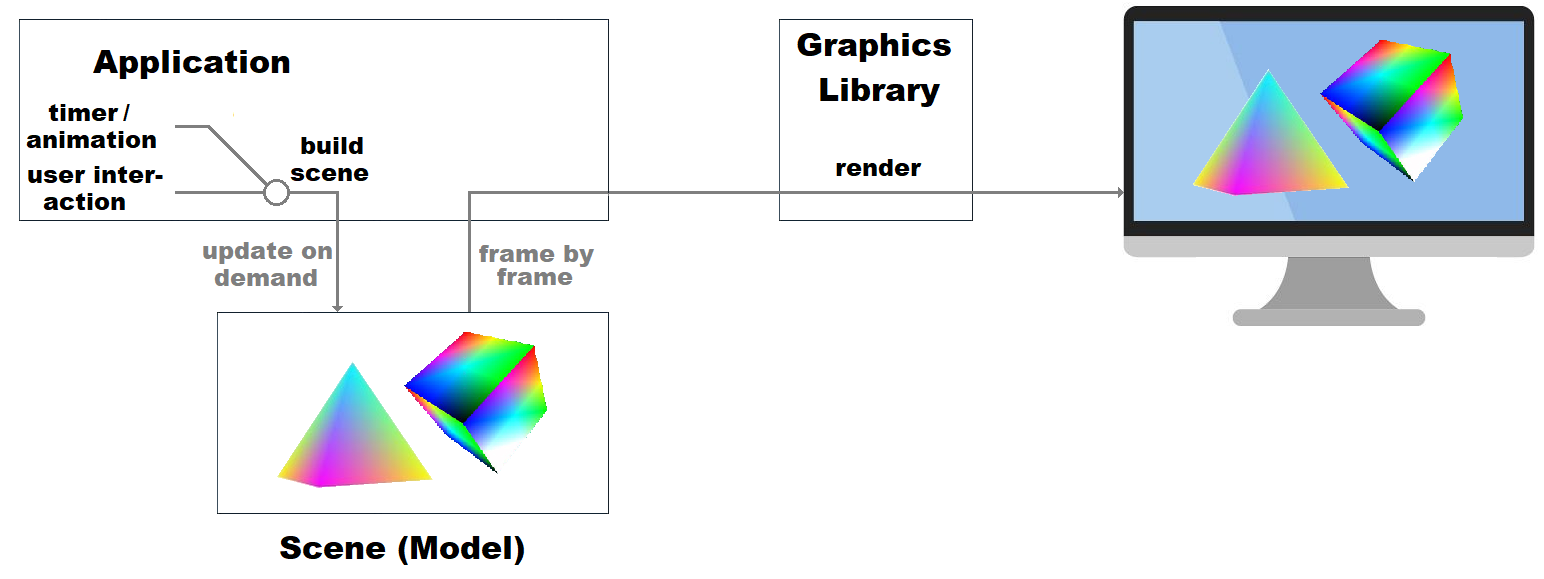
Mobile GPUs and Tile-Based Rendering
The Evolution of Mobile GPU Architecture
The evolution of mobile graphics processing represents one of the most significant architectural innovations in modern computing. While desktop GPUs have traditionally employed immediate mode rendering (IMR), mobile GPUs have pioneered a fundamentally different approach through tile-based deferred rendering (TBDR). This architectural divergence stems from the unique constraints of mobile devices: limited power budgets, thermal restrictions, and constrained memory bandwidth.
The transition from immediate mode to tile-based rendering represents more than just an optimization; it represents a complete reimagining of the graphics pipeline. As evidenced by Apple’s AGX architecture, which draws heavily from Imagination Technologies’ PowerVR lineage, these architectural choices have profound implications for software design, performance characteristics, and API utilization.
Immediate Mode Rendering: The Desktop Legacy
Traditional desktop GPUs implement immediate mode rendering, where the graphics pipeline processes geometry in a straightforward, sequential manner. When a draw call is submitted, vertices are processed immediately through the vertex shader, transformed to screen space, rasterized, and fragment shaders execute for each generated pixel. This approach mirrors the logical graphics pipeline as described by APIs like OpenGL and DirectX.
IMR architectures require substantial memory bandwidth because the entire framebuffer must be accessible during rendering. Every pixel write, blend operation, and depth test requires access to external memory. For desktop systems with dedicated VRAM and high-bandwidth memory interfaces, this approach is viable, but it becomes prohibitively expensive in mobile environments where memory bandwidth directly correlates to power consumption.
Tile-Based Deferred Rendering: The Mobile Era
TBDR represents a radical departure from immediate mode rendering by splitting the rendering process into two distinct phases: geometry processing (tiling) and fragment processing (rendering). This approach addresses the fundamental constraint of mobile GPUs: extremely limited on-chip memory, typically ranging from 1 to 5 megabytes.
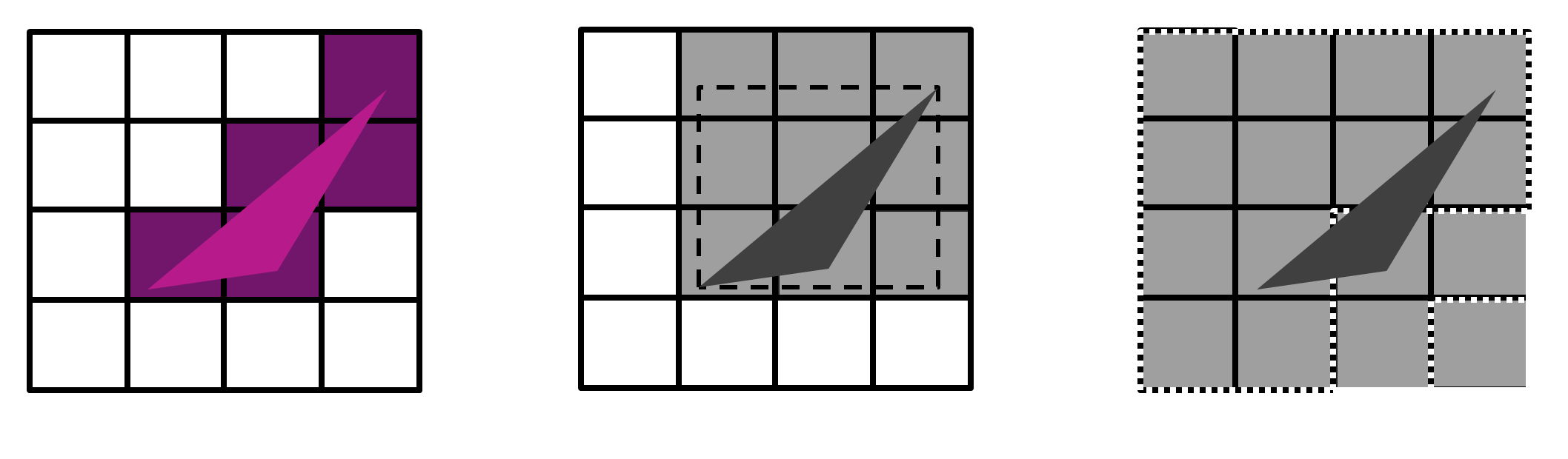
The Tiling Phase
During the tiling phase, all geometry is processed through vertex shaders and transformed to screen space, but no pixel shading occurs. The screen is divided into small rectangular tiles, typically 16×16 or 32×32 pixels, and the GPU constructs primitive lists that associate geometry with each tile. This process, called “binning”, ensures that subsequent rendering only processes geometry that actually contributes to each tile.
PowerVR’s “perfect tiling” algorithm represents a significant advancement over naive bounding box approaches. Rather than simply checking which tiles a triangle’s bounding box intersects, perfect tiling determines exactly which tiles contain actual triangle coverage, eliminating unnecessary processing of tiles that don’t contain visible geometry.
The Rendering Phase
Once all geometry has been binned, the GPU renders each tile independently to completion. The critical insight is that each tile’s working set—color buffer, depth buffer, and stencil buffer—fits entirely in fast, on-chip memory. This eliminates the constant memory traffic that characterizes IMR systems.
The deferred aspect of TBDR becomes apparent in the fragment processing phase. Unlike IMR systems that immediately shade fragments as they’re generated, TBDR systems can perform hidden surface removal before any pixel shading occurs. This means that only the front-most fragment for each pixel is actually shaded, eliminating overdraw entirely for opaque geometry.
Apple’s AGX Architecture
Apple’s AGX architecture, first introduced with the A11 Bionic, exemplifies the sophisticated engineering required to make TBDR work efficiently. The architecture draws heavily from Imagination Technologies’ PowerVR designs but incorporates Apple’s own innovations, particularly in handling complex rendering scenarios like multisampling and blending.
The Challenge of Sample Shading
The Asahi Linux blog post reveals the intricate complexity of implementing sample shading on AGX hardware. While traditional desktop GPUs can simply set a hardware bit to execute fragment shaders per-sample instead of per-pixel, AGX takes a fundamentally different approach. The hardware always executes shaders once per pixel, but provides instructions that allow different colors to be output to different samples within that pixel.
This design choice reflects the mobile-first nature of AGX. By exposing sample masks at the instruction level, the architecture enables sophisticated compiler optimizations that can hoist pixel-invariant calculations out of per-sample loops. This approach potentially achieves better performance than traditional per-sample execution while maintaining the flexibility needed for complex multisampling scenarios.
Software-Based Blending
Perhaps even more revealing is AGX’s approach to blending operations. While desktop GPUs typically implement blending in dedicated hardware, AGX performs blending entirely in software. This might seem like a regression, but it enables the compiler to optimize the interaction between multisampling and blending in ways that dedicated hardware cannot match.
The compiler can generate code that performs per-pixel fragment shading and per-sample blending, optimally balancing computational work and memory bandwidth. This software-centric approach exemplifies the mobile philosophy of trading specialized hardware for flexible, optimizable software implementations.
Vulkan API and Mobile GPU Optimization
The Vulkan API was designed with explicit awareness of tile-based rendering architectures, providing features that enable developers to leverage TBDR efficiently. Unlike older APIs that obscured architectural differences, Vulkan exposes concepts that map directly to mobile GPU capabilities.
Render Passes and Subpasses
Vulkan’s render pass concept aligns perfectly with TBDR architectures. A render pass defines a complete rendering operation to a set of attachments, while subpasses represent logical phases within that operation. On TBDR hardware, subpasses that have pixel-level dependencies can be merged by the driver, allowing multiple rendering operations to be performed while keeping intermediate results in tile memory.
The bandwidth savings from proper subpass usage are substantial. ARM’s documentation shows that using merged subpasses for deferred shading achieves 45% reduction in memory reads and 56% reduction in memory writes compared to separate render passes. This occurs because the G-buffer attachments never need to be written to external memory—they remain in tile memory throughout the lighting calculation.
Transient Attachments and Lazy Allocation
Vulkan’s VK_MEMORY_PROPERTY_LAZILY_ALLOCATED_BIT flag enables a critical optimization for TBDR systems. Render targets that are only used within a single render pass and never sampled externally can be marked as lazily allocated, meaning they exist only in tile memory and never consume external memory bandwidth.
This optimization is particularly powerful for intermediate rendering targets like G-buffers in deferred shading pipelines. On systems that support lazy allocation, these attachments consume zero external memory, providing both performance and memory usage benefits.
Pipeline Barriers and Memory Coherency
TBDR architectures require careful attention to pipeline barriers and memory coherency. Unlike IMR systems where memory operations occur immediately, TBDR systems may defer memory writes until tile completion. This means that poorly placed pipeline barriers can force unnecessary tile flushes, eliminating the bandwidth advantages of tiled rendering.
Vulkan’s explicit barrier model enables developers to provide precise information about memory dependencies, allowing TBDR drivers to optimize tile usage accordingly. However, this also means that suboptimal barrier placement can be particularly costly on mobile hardware.
Architectural Implications for Software Design
The fundamental differences between IMR and TBDR architectures have far-reaching implications for software design. Algorithms that perform well on desktop GPUs may be suboptimal on mobile hardware, and vice versa.
Geometry Complexity Trade-offs
TBDR systems excel with moderate geometry complexity but can struggle with extremely dense scenes. The binning process that makes TBDR efficient requires sorting geometry into tile lists, and this overhead grows with scene complexity. Desktop IMR systems, while less bandwidth-efficient, handle dense geometry more predictably.
This trade-off influences level-of-detail strategies, culling algorithms, and scene complexity targets for mobile applications. Developers must balance visual quality against the computational cost of geometry processing in ways that don’t apply to desktop development.
Draw Call Batching Considerations
Traditional wisdom suggests minimizing draw calls through batching, but TBDR architectures complicate this advice. While fewer draw calls generally improve CPU performance, excessively large batches can exceed tile memory capacity, forcing tile spills that eliminate bandwidth advantages.
Mobile-optimized rendering engines must balance draw call overhead against tile memory efficiency, often resulting in different batching strategies than their desktop counterparts.
Bandwidth-Conscious Algorithm Design
Every algorithm choice on mobile hardware must consider memory bandwidth implications. Operations that are “free” on desktop GPUs due to cache hierarchies may be expensive on mobile systems with limited bandwidth. This affects everything from texture streaming strategies to post-processing pipeline design.
Conclusion: The Future of Mobile GPU Architecture
Tile-based deferred rendering represents one of the most significant architectural innovations in graphics hardware, enabling the mobile graphics revolution that powers billions of devices today. The complex interplay between hardware capabilities and software optimization, exemplified by Apple’s AGX architecture and Vulkan’s mobile-conscious API design, demonstrates the sophisticated engineering required to balance performance, power efficiency, and programmability.
Understanding the architectural fundamentals is crucial for developers targeting mobile platforms. The bandwidth constraints that drove the development of TBDR continue to influence software design decisions, API usage patterns, and performance optimization strategies. As mobile devices continue to demand higher visual fidelity while maintaining battery life expectations, the principles underlying TBDR architecture will remain central to mobile graphics development.
As mobile devices continue to evolve, TBDR architectures are advancing in sophistication. Modern implementations support variable-rate shading, hardware-accelerated ray tracing, and advanced compute capabilities while maintaining the fundamental bandwidth advantages that make mobile graphics feasible.
The convergence of desktop and mobile architectures is also notable. Both NVIDIA and AMD have incorporated tile-based optimizations into their recent architectures, suggesting that the bandwidth efficiency advantages of TBDR are valuable even in high-performance desktop contexts.
Apple’s continued investment in AGX development, including features like hardware ray tracing acceleration and advanced compute capabilities, demonstrates that TBDR architectures can scale to meet increasing performance demands while maintaining their power efficiency advantages.
WIP